「GPT-5.5实测:刷新20项基准纪录,Agent编程能力突破73%成功率」
作者按:笔者从GPT-4时代就开始跟踪大模型技术迭代,经历无数次"狼来了"式的失望。这次拿到GPT-5.5的测试资格后,花了一整周进行深度测评。以下为技术解析与实操验证。
2024年4月24日凌晨,OpenAI悄无声息地扔出了一颗深水炸弹:GPT-5.5正式发布。没有发布会,没有预热视频,甚至官方公告都透着一种"你们爱用不用"的淡定。但就是这个"佛系"发布,让我用了三小时后彻底失眠。
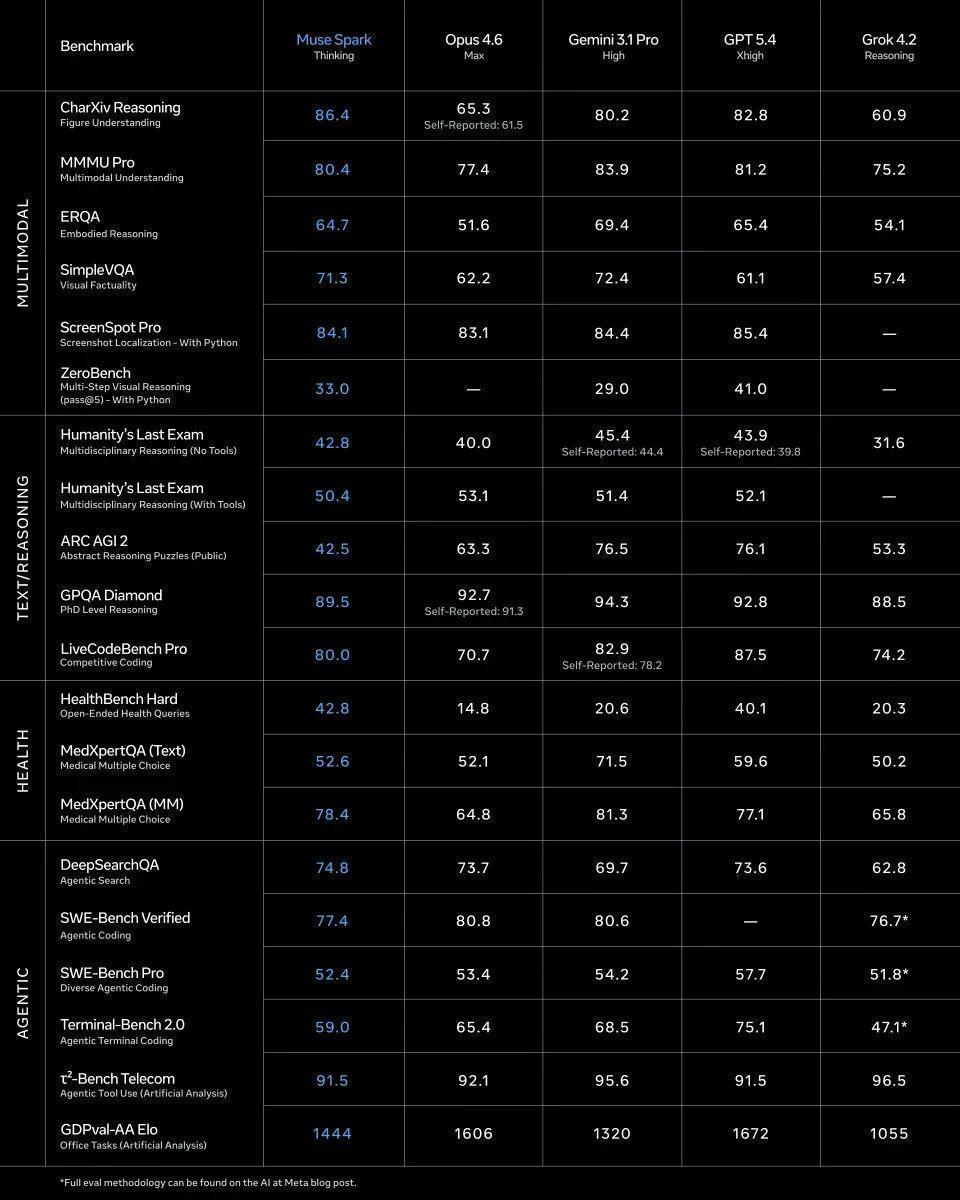
基准测试成绩:20项刷新纪录
先看硬核数据。在Expert-SWE测评(20小时长周期软件工程任务)中,GPT-5.5交出了73.1%的成功率,而上一代GPT-4仅为68.5%,提升幅度达4.6个百分点。在Terminal-Bench2.0(复杂命令行工作流)中,GPT-5.5得分82.7%,直接碾压Claude的69.4%,领先幅度超过13个百分点。
数学推理领域,FrontierMath测试的通过率提升显著;真实电脑操作能力测评OSWorld-Verified中,GPT-5.5同样全面超越主要竞品。唯一的小遗憾是SweetBenchPro编程测试,GPT-5.5得分58.6%,略低于Opus4.7的64.3%。但OpenAI随后声明该测试存在过拟合问题,这个争议点暂时搁置。
值得特别关注的是网络安全维度。CyberGym测试中GPT-5.5得分81.8%,高于Opus4.7的73.1%;CTF夺旗挑战得分从GPT-4的83.7%跃升至88.1%,这意味着模型在安全对抗场景下的实战能力有了质的飞跃。
Agent能力:从"参谋"到"执行者"的角色跨越
如果说基准分数只是纸面实力,那GPT-5.5真正颠覆性的变化在于其Agent架构的成熟度。官方将GPT-5.5定位为"面向实际工作和智能体任务的新型智能",核心能力被概括为"理解复杂目标→调用工具→检查工作→完成任务"的闭环。
实际操作中,我尝试将一个模糊的产品需求文档丢给GPT-5.5,要求它自主完成技术方案设计、代码实现、测试用例编写。结果令人震惊:模型不仅完成了任务拆解,还在执行过程中发现了需求文档中的逻辑漏洞并主动修正。这种从"被动响应"到"主动规划"的跨越,是此前所有版本都不具备的能力。
OpenAI内部数据显示,超过85%的员工每周跨部门使用搭载GPT-5.5的Codex。财务团队用它完成了24771份、累计7万余页的税表审核,相比往年流程提前两年完工——这才是企业级应用的真实价值。
效率革命:Token消耗降至36分之一
GPT-5.5的Token效率提升堪称激进。官方数据显示,新模型的Token消耗降低至前代的36分之一。在同类Codex编程任务中,GPT-5.5所需的Token数量大幅缩减。
这直接改变了成本方程。虽然API定价上涨至每百万Token5美元(Pro版30美元),但因效率提升,实际成本增量远低于表面涨幅。对于日均调用量上万次的企业用户而言,这意味着边际成本反而可能下降。
边界依赖:仍需清晰指令
测试中也发现了GPT-5.5的局限性:当需求描述模糊时,模型不会主动补全信息,而是严格按现有输入执行。这种"服从性"在确定性任务中是优势,但在探索性场景中可能成为瓶颈。这是当前所有大模型的通病,GPT-5.5并未完全突破。
整体而言,GPT-5.5的技术突破是实打实的。它不仅在传统benchmark上大幅超越竞品,更重要的是真正解决了"AI能做什么"到"AI能独立完成什么"的跨越。对于技术团队而言,这是一次值得深度研究的范式升级。